TL;DR: Bessemer's latest AI survey shows a sharp split between engineering and the rest of the company. The reason is not that engineers are more excited about AI. It is that code is unusually machine-legible: readable, testable, observable, and easy to verify. Most business workflows were built for human workaround, not machine participation.
Point an AI agent at your CRM and ask it to forecast the quarter.
It pulls the opportunity stages. Half of them mean slightly different things depending on the rep. Next steps are stale. Renewal risk is buried in call notes. The real account context lives in Slack, the CSM's head, and one spreadsheet someone updates before the Monday pipeline meeting.
The model can still produce a forecast. It may even sound convincing. But now a human has to audit every assumption behind it, because the system never made the work readable in the first place.
That is the part most AI strategies skip.
AI does not begin with intelligence. It begins with legibility.
The Split Bessemer Found
Bessemer Venture Partners just published its State of Working with AI report, based on a survey of 173 leaders across 113 portfolio companies.
The headline number is not that companies are interested in AI. That part is obvious. Eighty-six percent of leaders expect AI to meaningfully change how their teams operate in the next 12 months.
The more useful finding is that AI adoption is not moving through the company as one neat curve. It is breaking apart by function.
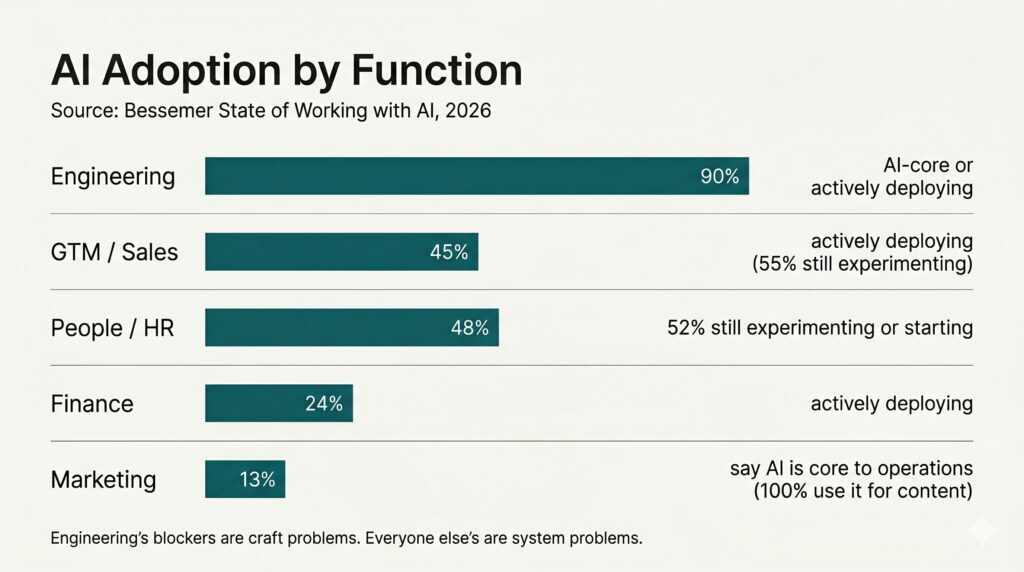
Engineering is already in a different operating reality. Bessemer found that 90% of Tech & Engineering teams are either AI-core or actively deploying AI. Among engineering teams, 77% use Claude Code and Cowork, and 50% use Cursor.
Then the curve bends.
Finance is much earlier: only 24% are actively deploying. GTM has momentum, with 45% actively deploying, but 55% are still experimenting. People teams are even earlier, with 52% still experimenting or just getting started. Marketing is the strangest case: 100% use AI for content, but only 13% say AI is core to operations.
The lazy explanation is that non-technical teams are slower adopters. They need more training, more licenses, more pressure from leadership.
My read is simpler: some work is ready for machines to participate in, and some work is not.
The Work Has to Be Legible
Engineering did not win the first wave of AI because engineers are better at prompts. It won because software work was already organized in a way machines can understand.
Code has four properties most business workflows do not.
First, the inputs are readable. A codebase lives in files. Those files are version-controlled. The history is visible. The dependencies are inspectable.
Second, the output is bounded. The model is not trying to satisfy a vague human preference from scratch. It is writing a function, fixing a bug, generating a test, refactoring a component.
Third, the feedback loop is fast. The code compiles or it does not. Tests pass or fail. Linters complain. CI catches regressions. The machine gets a signal quickly.
Fourth, the work happens inside tools. The IDE, repo, terminal, issue tracker, and CI system give the agent a place to act and a way to see the result.
That combination is rare. It makes engineering unusually machine-legible.
The model is still imperfect. It writes bad code. It invents APIs. It misses edge cases. But the surrounding system catches many of those failures quickly, and the human reviewer knows where to look.
That is why the engineering AI playbook moved so fast. It was not dropped into empty space. It landed inside a workflow already designed around explicit inputs, visible changes, and repeatable checks.
Most corporate work does not look like that.
The Blockers Are Not the Same Shape
This is where the Bessemer data gets interesting. The blockers reported by each function are not just different. They are different kinds of problems.
Engineering teams report code quality and review bottlenecks. Those are real problems, but they are mostly inside the craft. A team can improve review patterns, add evaluation harnesses, change coding standards, or tune how agents are used.
Finance leaders report data quality and system fragmentation. That is not a prompt problem. The issue is that the data often lives across ERPs, billing systems, warehouses, spreadsheets, and reporting layers. A finance team cannot make AI reliable if the basic facts of the business are scattered across systems that disagree with each other.
GTM leaders report tool sprawl, no clear winner, and CRM hygiene. Again, that is not an AI fluency problem. It is a legibility problem. If the CRM is full of stale stages, duplicate accounts, and fields that mean different things to different reps, an AI agent is not operating on business reality. It is operating on residue.
People teams report privacy and compliance concerns. That is not reluctance. It is rational caution. When the work involves hiring, performance, compensation, or employee relations, the cost of a bad output is high and the rules are still being written.
Marketing teams report brand safety and quality control. This one is easy to misunderstand. Yes, AI can generate content. That is precisely why the problem shows up. When content production gets cheap, the bottleneck moves to judgment: what is on-brand, what is legally safe, what is strategically useful, what should never be said. Many teams never had to write those standards down because human throughput was the natural limiter.
Customer Success teams report data fragmentation and difficulty proving impact on NRR. CS work is full of context, but that context is spread across product usage, support tickets, customer calls, CRM notes, renewal history, and the CSM's own memory. The work is rich, but much of it is not visible to software.
Once you see the pattern, the adoption gap looks less mysterious. Engineering's AI blockers are mostly craft problems the team can fix from inside. Everyone else's blockers are system problems the team adopting AI doesn't own.
The Engineering Playbook Does Not Port
This is the mistake I see in a lot of AI rollout plans: they take the engineering curve and treat it as the company curve.
It goes something like this: developers adopted AI quickly, so we should be able to reproduce that pattern in sales, finance, HR, marketing, and support. Buy the tools. Train the users. Ask each function to find use cases. Track adoption.
That works only when the workflow is already legible enough for a machine to participate.
If the workflow depends on tribal knowledge, disconnected data, human memory, and subjective review, the agent does not remove work. It moves the work. Someone still has to reconcile the spreadsheet, interpret the account history, check the policy risk, clean the CRM field, or decide whether the output is any good.
This is why some AI pilots feel exciting in week one and exhausting by month three. The demo example is clean; the operating environment is not. Leaders then call it an adoption problem, when often it is a legibility problem.
The Next Advantage Is Boring
The next phase of AI ROI won't come from giving every function another chatbot. It will come from making more of the company readable enough for software to participate in the work.
That means work most executives don't instinctively file under "AI strategy":
- cleaning customer and revenue data,
- defining quality standards and decision rules,
- creating faster review loops,
- exposing internal systems through safe APIs,
- clarifying what AI is allowed to touch.
None of this has the shine of a model launch. It will not look impressive in a screenshot. But it is the difference between AI as a clever assistant and AI as an operating capability.
The companies that understand this will stop asking only, "Which teams are using AI?"
They will ask better questions:
- Which workflows have readable inputs?
- Which outputs can be checked quickly?
- Which decisions still live only in someone's head?
- Which systems disagree with each other?
- Which teams are being asked to adopt AI on top of infrastructure they do not control?
Those questions are less glamorous. They are also much closer to the work.
Monday Morning Checklist
For Executives
☐ Stop treating AI adoption as a seat-count problem. Ask which workflows are legible enough for AI to act on.
☐ Shift some AI budget toward data cleanup, CRM hygiene, process documentation, and system integration.
☐ Make technical leaders accountable for enabling AI value in business functions, not just inside engineering.
For Functional Leaders
☐ Pick one workflow your team wants AI to improve. Write down where the input data lives, who owns it, and how often it is wrong.
☐ Identify the step that still depends on tribal knowledge. Turn it into a written rule, checklist, rubric, or review standard.
☐ Do not launch pilots that depend on systems your team cannot change. Escalate the system dependency first.
For Data, IT, and Platform Leaders
☐ Build a legibility map by function: readable inputs, structured outputs, feedback loops, tool access, policy boundaries.
☐ Prioritize integrations that make high-value workflows observable and checkable.
☐ Measure your roadmap not only by uptime and tickets closed, but by how much downstream AI work it unlocks.
The single takeaway: AI works best where the work is readable, bounded, and checkable. Engineering had that first. The companies that win the next round will be the ones doing the unglamorous work of making the rest of the business legible to a machine.