How does Google know exactly which webpage you’re looking for out of trillions? How does your phone know the next word you’re about to type? And what does all of this have to do with a 100-year-old math feud over a Russian poem?
The answer to all these questions lies in a surprisingly simple and powerful idea: the Markov chain. And understanding this idea is key to understanding not only where AI came from, but where it might be taking us next.
The Simple Idea: What Happens Next Depends Only on What's Happening Now
Imagine trying to predict tomorrow's weather. You could look at the weather from a year ago, a month ago, or last week. But your best bet is probably just to look at the weather today. Is there a storm front moving in right now? What's the current temperature and pressure?
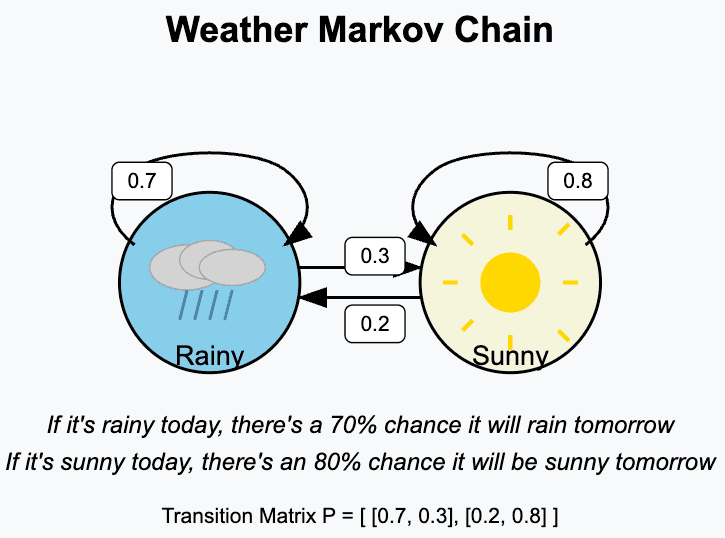
This is the core insight of a Markov chain, a concept pioneered by Russian mathematician Andrey Markov around 1906. He theorized that for many complex systems, you can make a pretty good prediction about the next step by only looking at the current state, ignoring almost everything that came before. It’s a "memoryless" way of looking at the world.
Markov proved his point by analyzing Alexander Pushkin's poem, "Eugene Onegin." He showed that the probability of the next letter being a vowel or a consonant depended heavily on the current letter. By creating a simple "chain" of probabilities (if the letter is a vowel, there's an X% chance the next is a consonant), he could model the structure of the Russian language.
This might seem like a simple academic exercise, but this idea—modeling complex dependent systems with simple, memoryless rules—would eventually be worth trillions.
The First Trillion-Dollar Application: Google's PageRank
Fast forward to the late 1990s. The internet was exploding, but finding anything was a mess. Early search engines just counted how many times a keyword appeared on a page, which was easy to cheat.
Two Stanford PhD students, Larry Page and Sergey Brin, had a better idea. What if the importance of a webpage wasn't just about its own content, but about how many other important pages linked to it?
They imagined a "random surfer" clicking links on the web. The pages this surfer spent the most time on would, by definition, be the most important. This is a perfect Markov chain:
- Each webpage is a state.
- The links on that page are the transitions to the next state.
The surfer's next move depends only on the links on their current page (the current state). They don't need to remember the 50 pages they visited before. By modeling the entire web as a massive Markov chain, Page and Brin created PageRank, the algorithm that powered Google and turned a sea of information into a searchable index. A 100-year-old piece of math from a Russian poem became the foundation of the modern internet.
The Evolution of Prediction: From Letters to Tokens
But Markov's original idea was about predicting the next piece of text. This concept has evolved dramatically, leading directly to the large language models (LLMs) we use today.
- Level 1: Character by Character. Early experiments could predict the next letter in a sentence (or password). The results were mostly gibberish, but you could sometimes spot real words forming, like "the" or "and."
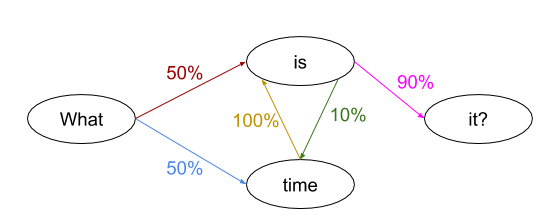
- Level 2: Word by Word. The next step was to predict the next word. This created sentences that were often grammatically correct but made no sense, like: "The head and in frontal attack on an English writer that the character of this point is therefore another method..."
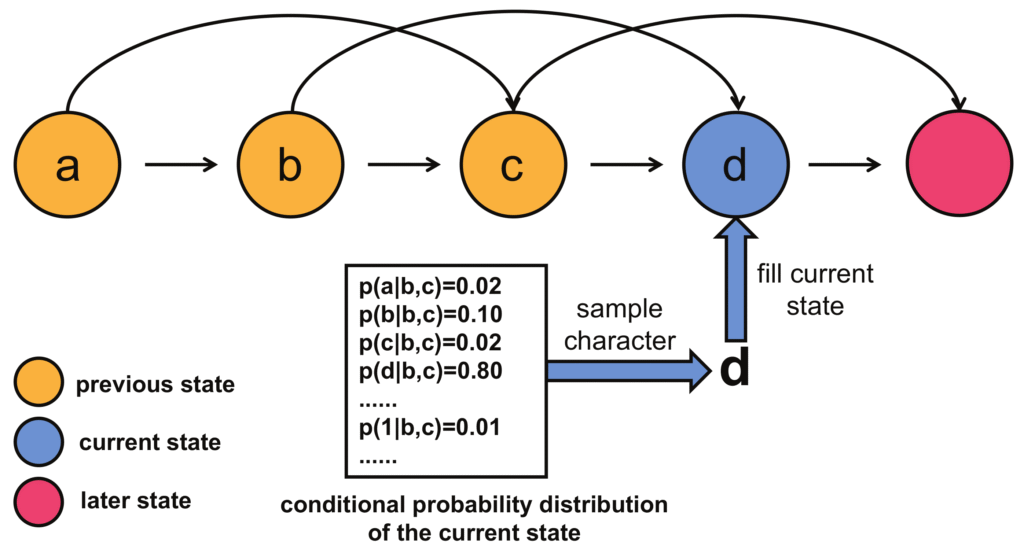
- Level 3: Tokens and Attention. This is the modern leap. LLMs don't just see words; they see "tokens," which are smart chunks of text. More importantly, they use a mechanism called "attention." This is where we fundamentally break from the "memoryless" property of a simple Markov chain.
Mathematically, the memoryless property states that the probability of the next state depends only on the current state. The "attention" mechanism gives the model a selective, long-term memory. It looks back at all previous tokens in the prompt and assigns a weight, or "attention score," to each one, deciding which are most relevant for predicting the next token.
For instance, in the sentence "After walking along the river, the man sat on the bank," the attention mechanism allows the LLM to look back at the word "river," assign it a high attention score, and understand that "bank" refers to the side of a river, not a financial institution. It's no longer memoryless; it's context-aware.
Beyond Memoryless: The Unpredictable Future of Attention
So we've gone from the elegant simplicity of memoryless Markov chains to the complex, contextual power of LLMs with "attention." But this leap introduces a strange and powerful new dynamic: the feedback loop.
LLMs are now generating a massive amount of text, code, and images that are being published online. This AI-generated content is becoming part of the training data for the next generation of AI models. We've created a global feedback loop where AI starts learning from itself.
What happens when an AI's main source of information about the world is... content created by other AIs?
What Happens Next? From Global Loop to Curated Systems
If we keep feeding AI its own output, where does this feedback loop lead? The future likely isn't one single outcome, but a splintering of possibilities based on how we manage these loops.
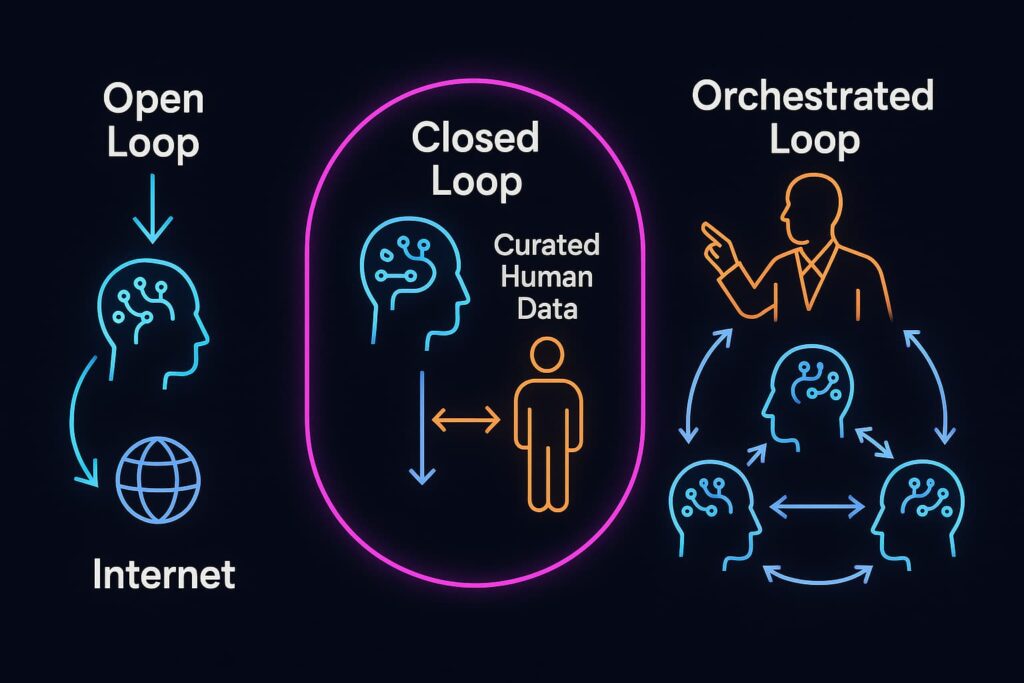
- The Open Loop (Model Collapse): This is the default, chaotic path. In the vast, uncurated expanse of the public internet, AIs trained on other AI content could lose touch with the richness and nuance of true human creativity. They might converge on a statistically average "stable state," producing increasingly generic content until innovation grinds to a halt. This is the "Great Stagnation," where future AIs become less capable as their training data gets polluted by their own synthetic ancestors.
- The Closed Loop (Walled Gardens & Digital Authenticity): As a defense against model collapse, companies will create "clean rooms" of proprietary, human-verified data. Human-created content becomes a premium, verifiable asset, leading to an industry of "Digital Authenticity." The highest-quality AIs will be trained inside these walled gardens, creating a divide between premium, reliable models and the chaotic, unpredictable models trained on the open internet. Authenticity becomes a competitive moat.
- The Orchestrated Loop (The Rise of "Markov Chain Chefs"): This may be the most interesting future. As the paper "Markov chain tricks" aptly puts it, "problem solving is often a matter of cooking up an appropriate Markov chain." This insight scales powerfully to the AI era. Just as mathematicians and scientists design specific Markov chains to solve complex problems, like sampling from an otherwise intractable distribution in MCMC, the most valuable human skill may not be generating content, but designing the systems that generate it.
The future expert becomes a "Markov Chain Chef" or a "System Conductor", someone who can design, couple, and fine-tune ensembles of specialized AI agents and their data feedback loops to achieve specific, novel outcomes. We stop being just users of a single model and become architects of complex, creative AI systems.
The simple, predictable math of the past gave us a powerful tool. The complex, attention-based systems of today give us a powerful but unpredictable partner. The question is no longer just "what's the next word," but who will have the vision to design the systems that decide which words come next?
It brings the original debate full circle. Markov's work began by questioning the nature of free will in a predictable world. The technology that followed now asks us what human vision and agency truly mean when we have the power to design the very systems that shape our reality.